
揭秘OpenAI o1 Self-Play RL技术路线,未来智能之路的无限可能

本文探讨OpenAI的o1 Self-Play RL技术路线,揭示了智能发展的未来趋势和无限可能。文章介绍了该技术路线的核心原理,探讨了其在智能领域的应用前景,包括机器学习、人工智能等领域。通过自我对弈强化学习等技术手段,智能系统得以自我进化,不断提升能力。展望未来,该技术路线有望推动智能技术的飞速发展,为人类创造更多可能性。
目录导读:
随着人工智能技术的飞速发展,OpenAI的o1 Self-Play RL技术路线成为了业界瞩目的焦点,本文将深入探讨这一技术路线的演进过程,揭示其背后的原理和应用前景。
一、引言
在人工智能领域,自我对抗强化学习(Self-Play RL)技术日益受到关注,OpenAI作为该领域的佼佼者,其o1 Self-Play RL技术路线的进展备受期待,自我对抗强化学习能够让智能体在没有人类数据的情况下,通过自我对弈来学习和提升技能,这一特点为许多领域的应用提供了广阔的空间。
二、OpenAI o1 Self-Play RL技术概述
OpenAI的o1 Self-Play RL技术是一种基于自我对抗的强化学习技术,它通过智能体之间的自我对弈,模拟真实环境中的交互,从而实现智能体的自我学习和能力提升,该技术路线的核心在于通过自我对弈产生的数据来训练模型,进而优化决策策略。
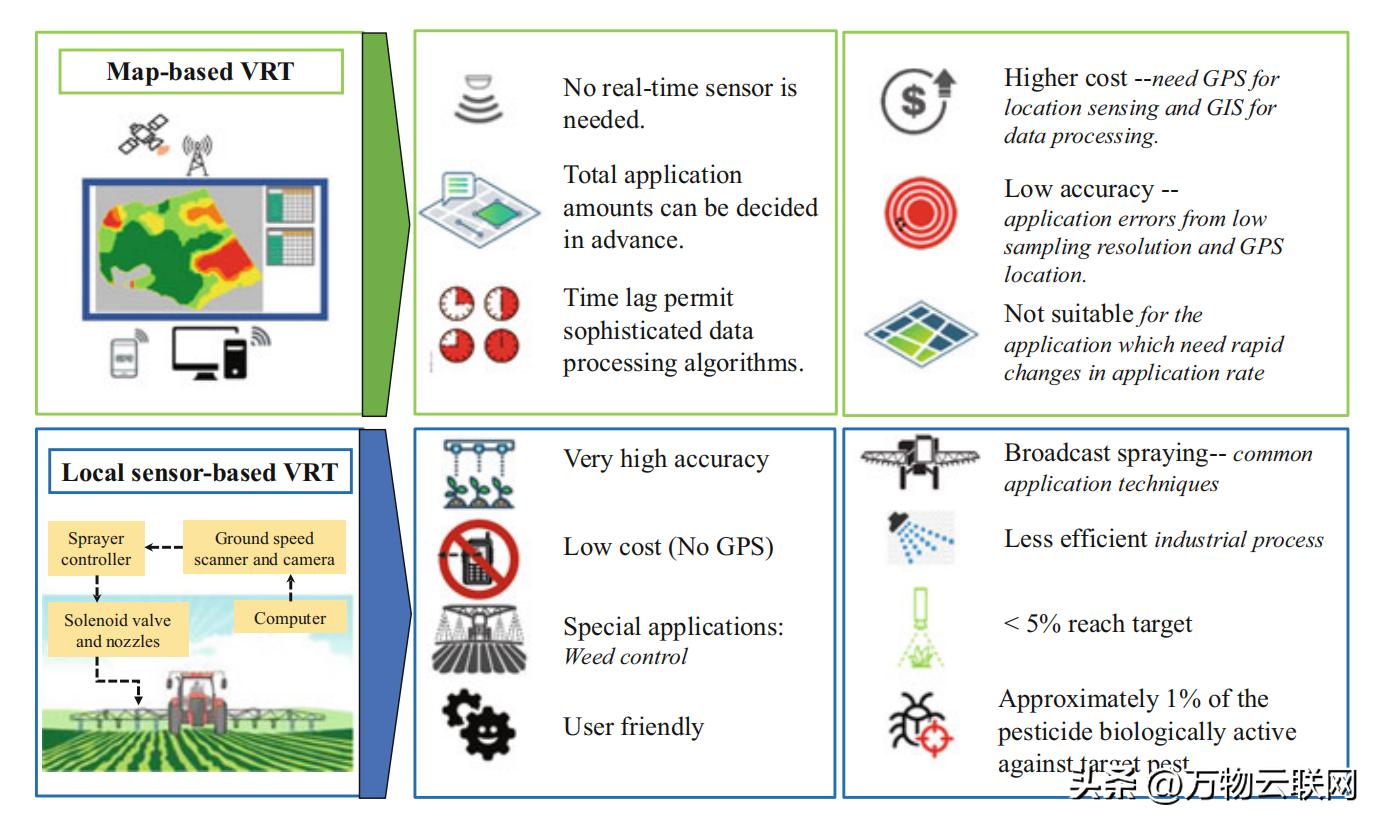
三、技术路线推演
初始阶段:模拟环境创建
在自我对抗强化学习的初始阶段,首先需要创建一个模拟环境,以便智能体进行自我对弈,OpenAI通过构建高度逼真的模拟环境,为智能体的学习提供了基础。
自我对弈:智能体交互学习
在模拟环境中,智能体通过自我对弈来模拟真实环境中的交互,通过对弈过程中的胜负结果,智能体能够逐渐学习到优化决策的策略。
数据收集与分析:优化模型
自我对弈过程中产生的大量数据被收集并进行分析,这些数据用于训练模型,进一步优化智能体的决策能力。
模型评估与改进:持续迭代优化
经过训练后的模型需要进行评估,以确定其性能是否达到预期,根据评估结果,模型会进行持续改进和优化。

融合多智能体技术:提升智能水平
为了进一步提升智能体的能力,OpenAI将多智能体技术融入到o1 Self-Play RL技术路线中,多智能体的协同和竞争,使得智能体的学习能力得到进一步提升。
法规遵循与伦理考量
在技术路线推演过程中,OpenAI始终遵循相关法规,确保技术的合法性和合规性,对于人工智能的伦理问题也进行了深入考量。
技术挑战与突破
自我对抗强化学习技术面临着诸多挑战,如模型泛化能力、数据效率等,OpenAI通过持续的研究和突破,不断克服这些技术难题。
生活应用前景展望
o1 Self-Play RL技术路线在生活应用中的前景广阔,从游戏、机器人到自动驾驶等领域,都有着广泛的应用潜力。
未来发展趋势预测
随着技术的不断进步,未来OpenAI的o1 Self-Play RL技术路线将更加成熟和普及,智能体将在更多领域发挥重要作用,为人类生活带来更多便利和进步。

四、结语
OpenAI的o1 Self-Play RL技术路线为人工智能领域带来了革命性的突破,通过自我对抗强化学习,智能体能够在没有人类数据的情况下进行自我学习和能力提升,这一技术路线的广泛应用和深入发展,将为人类生活带来更多惊喜和进步,我们期待着这一技术在未来的更多突破和应用。









 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号